Integrations do not always require the formal use of an API and server-to-server integrations! With ClauseBase’s drag & drop integrations in a Q&A, you can get quite far, without having to configure any servers or having to get clearance from your security-experts.
General idea
The general idea is that you configure a Q&A to receive external data. This external data can take different shapes, e.g. an Excel-file, a scanned PDF, a JSON-file, structured text, etc. You then configure certain rules on how to extract and convert relevant data, and transfer that data into Q&A-answers.
Within ClauseBase you do this through two dedicated panels in the Q&A:
- the External data input panel (to configure data extraction and conversion rules); and
- the Test external data panel (to interactively test those rules with sample input)
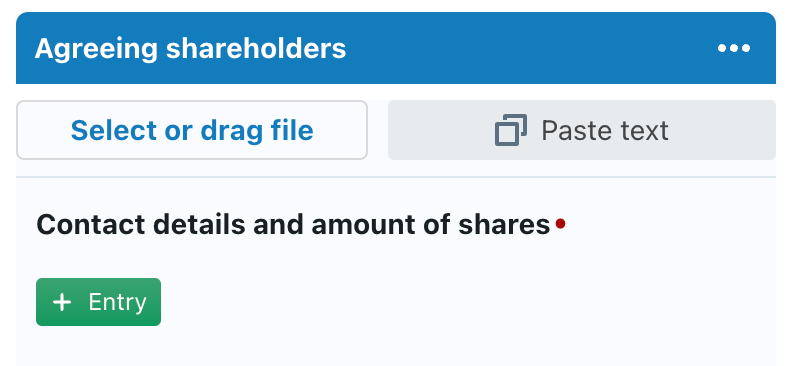
Finally, you also add a separate type of “question” to the Q&A that will represent the area where end-users can upload a file or paste text.
Use cases
The drag & drop integrations have many different use cases. Some ideas:
- In some organisations, decentralised HR-managers gather administrative data from new employees in a simple Excel-sheet that is then uploaded into the company-wide HR-system (e.g., Workday or SAP SuccessFactors). That same administrative data can also be used to fill answers in ClauseBase.
- In a similar vein, some organisations create an “onboarding sheet” with various information about a new employee (e.g., department, internal number, manager’s name, etc) and send it as a nicely formatted PDF-file or Word-file to the employee. If that file follows a similar structure, you can have its data automatically extracted.
- Certain requests to draft a contract may arrive in emails for which (a dedicated part of) the body has a predefined structure that contains relevant data. Such data is a candidate for automatic transferal into a questionaire’s answers.
- While ERP-systems such as SAP and Salesforce allow for deep integrations (e.g., through APIs), such integrations require strong involvement of the IT-department, or even the security department — which may trigger separate budgets, waiting lists, clearances, etc. Instead of such deep integrations, it could be interesting to create a light integration, where a button is programmed on the ERP-side that copies structured data (e.g., in JSON-formatted) to the clipboard of the end-user’s computer. That data can then be pasted at ClauseBase-side, whereby relevant data is extracted and inserted into various questionaire answers. Because the end-user’s computer can be assumed to be secure, no security clearance is likely required.
- Some accounting or case management systems simply do not allow any IT-integrations at all, but do allow to export data in a predefined format (e.g., a Word-file or CSV-file). Such files can be easily uploaded into a ClauseBase-questionnaire.
- When such external system does not allow any direct export (e.g., some mainframe terminal applications), you could ask the user to take a screenshot of the user interface, and drag/upload that screenshot into ClauseBase.
- When you want to extract data from an HTML page (e.g. a specific website), you can ask the user to copy/paste the entire content of that website and use an XPath extraction in order to extract a specific piece of information on that page.
Preparing extraction rules
The External data input panel allows you to configure the data extraction rules on a per-questionaire basis. It consists of three different sub-panes: Overview questions and Configure question and Pre-process.
Overview questions
In this subpane, you get a list of all your cards and questions, preceded by an icon that indicates whether the question has at least one data extraction rule assigned to it (as is the case with the Name and first name in the screenshot below). Table-based questions will have their columns separately listed.
When you click on a question (or table-column), you are transferred to the Configure question sub-pane, from where you can configure the data extraction rules for that particular question/column.

Configure question
In this sub-pane, you can configure the data extraction rules for the selected questions.
At the top of this sub-pane, there is a checkbox Auto-switch question. When checked, the sub-pane will automatically switch to whatever question you happen to select in the Cards panel, which avoids that you have to constantly go back-and-forth between the Overview questions and Configure question sub-panes in order to switch questions. A third method to switch questions, is by clicking the blue Switch to selected question button after you have selected some question in the Cards panel.
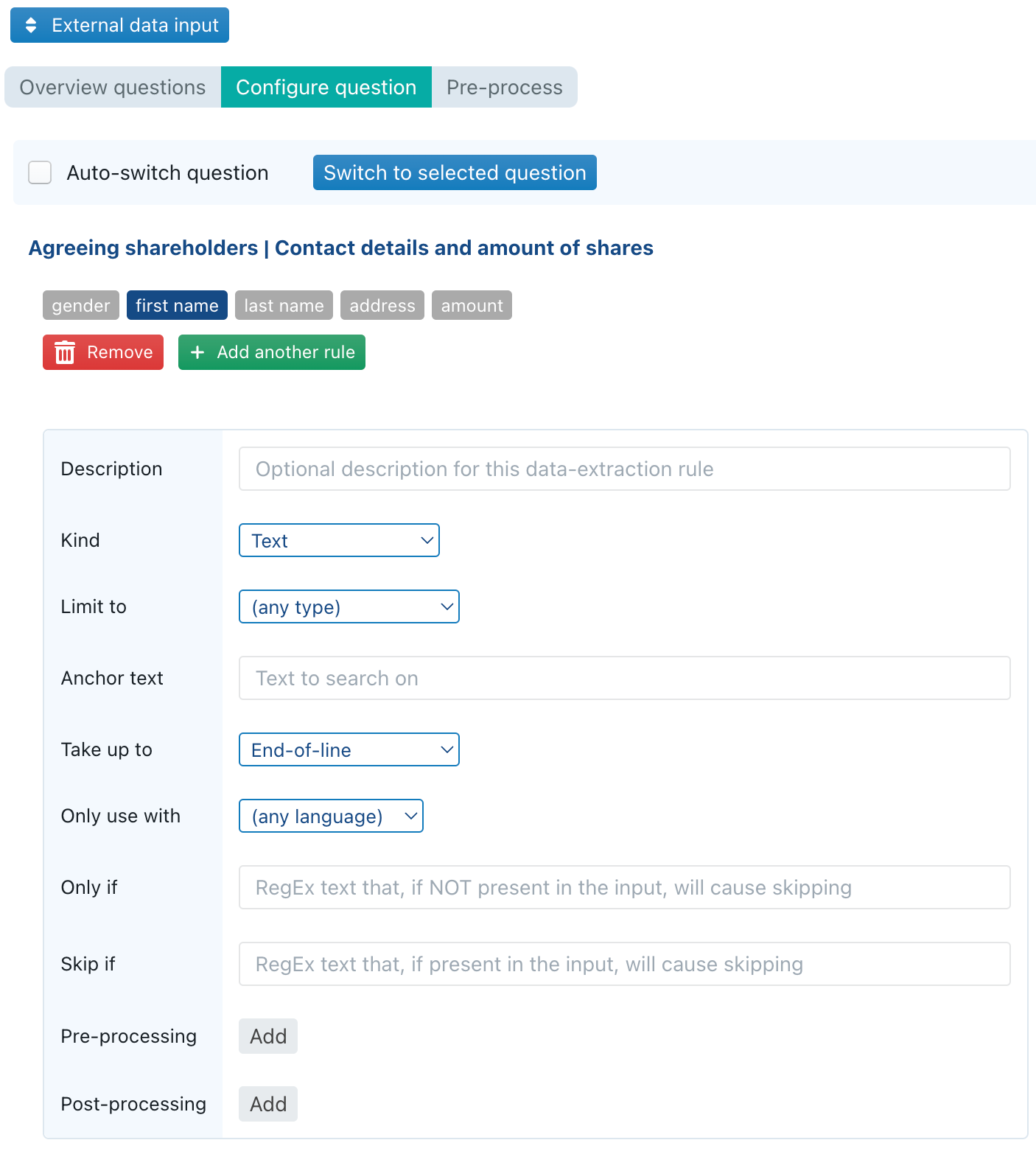
For each question, you can configure an unlimited number of data extraction rules. The idea is that each of these rules will be tried in successive order; as soon as some data extraction rule results in a succesful extraction, the subsequent rules for that question are ignored.
This multi-rule setup allows you to anticipate several different data-inputs — e.g., if you expect that employee data will sometimes be delivered as a PDF-file, and sometimes as an Excel-file or as part of the body of some email.
Pre-process pane
In this pane you can insert Clojure code to pre-process any text file.
The content uploaded/pasted by the end-user is provided in a var called input, and you are expected to return a string. That string will then be used for any subsequent processing described below.
See our separate page on using Clojure custom functions.
Types of input
- Word-files (.DOC or .DOCX) are extracted into plain text.
- Image-files (e.g., a .PNG or .JPG, but also PDF-files containing scans) are converted into text using optional character recognition (OCR).
Kind “Text” and “RegEx”
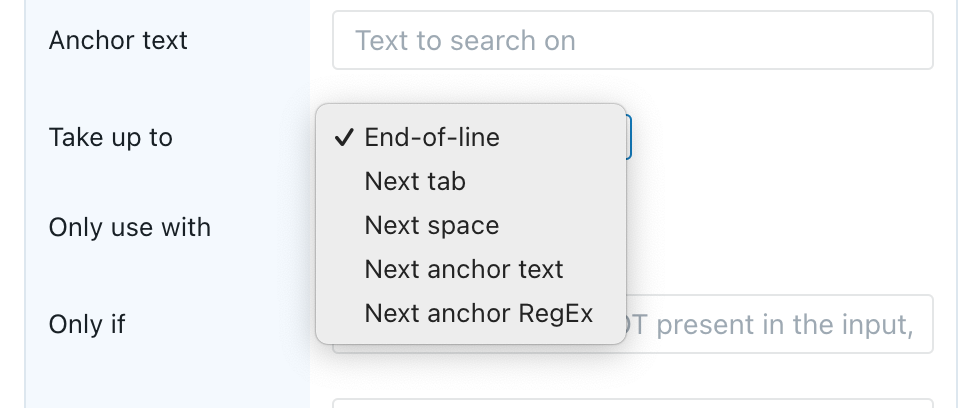
This data type allows you to start from some input text (e.g., copy/pasted text, or an entire Word-file, or an entire .TXT-file), search for a starting point, and extract a number of characters.
- The Anchor text allows you to specify the starting point. For example, if a text-file contains a line
Alpha beta: gamma, and you want to extract the part after theAlpha beta:, you can specify that text as the anchor text. For kind “RegEx”, you can also specify a regular expression, see below. - The Take up to allows you to specify a twhich point the extraction should stop:
- With End-of-line all text between the end of the anchor and the end of the line will be extracted. For example, if the input would be
Alpha beta: gamma deltathengamma deltawill be extracted ifAlpha beta:is specified as the anchor and End-of-line is used. - With Next tab/space all text between the end of the anchor and the next tab/space will be extracted. For example, if the input would be
Alpha beta: gamma deltathen onlygammawill be extracted ifAlpha beta:is specified as the anchor and Next space is used. - With Next anchor text/RegEx all text between the end of the anchor and the start of some next anchor will be taken. (See below for a description of RegEx.)
- With End-of-line all text between the end of the anchor and the end of the line will be extracted. For example, if the input would be
- Note that, while searching, the data extraction ignores capitalisation, so it does not matter whether you specify
AlphaoralphaoraLPHaas the anchor. The text that actually gets extracted will be in its original capitalisation, however.
Regular Expressions (often abbreviated as “Regex”) are a kind of mini-programming languages that allow advanced searching and extraction of text.
There are many websites online that allow you to learn about, and interactively experiment with, these regular expressions. A good example is http://www.regex101.com/ (the regex “dialect” used by ClauseBase is the JavaScript Regex). Many introduction tutorials exist — see, for example, https://regexone.com/.
Regular expressions can be useful if your anchoring points do not consist of a single unique word in a line of text. For example, if some line of text contains a company number somewhere (e.g., Customer's company number: BE0123456789), you cannot simply use BE as the anchoring point, because different countries will have different prefixes. In such case, you can use a RegEx to search for the two initial prefix characters.
Kind “Spreadsheet cell”
This allows you to extract the contents of a certain cell (e.g., “B5”) from some .XLSX-file that was uploaded by the end-user. The data type of the extraction will depend on the combination of the cell’s content and the target-question:
- Boolean cell-content will result in true/false if the target-question is true/false; otherwise an error will be generated.
- Textual cell-content will result in text if the target-question is also text; otherwise an error will be generated.
- Date cell-content will result in a date if the target-question is also date-based; otherwise an error will be generated.
- Numeric cell-content will result in a whole number, floating point number or currency (using the end-user’s default currency), depending on whether the target-question expects a whole number, floating point number or currency; otherwise an error will be generated.
Some additional notes:
- You can refer to different sheets in an Excel-file by using the standard Excel notation sheetname!cellname or (when spaces are contained within the sheet’s name) ‘sheet name with spaces‘!cellname — for example, if you have a sheet with name ‘Alpha Beta’, you can refer to its cell B5 using
'Alpha Beta'!B5.
Attention: when no sheet-name is provided, any sheet’s name will work. If you then upload an Excel-file that contains multiple sheets, the last sheet’s value in that cell (if filled in in that sheet) will be taken. - For table-based questions, you can fill columns by referring to a range of data cells (either horizontally or vertically) — e.g.
A1:A99or B2:Z2 (optionally prefixed by a sheet name, e.g.'Alpha Beta'!A1:A99. Of course, all those cells within the range should have the same type of data. Blank cells will be ignored.
Kind “JSONPath”
JSONPath allows you to use the JSONPath language to extract field-data from JSON-files. For a full description and some examples, you can visit the original JSONPath website, or alternatively an interactive playground.
The following operators are available for your use (see also the limitations for the Clojure-implementation, particularly relating to the allowed slicing / index operators):
- $ to select the root of the object, i.e. the starting point
.to descend to a single child..for recursive descent to select all children*and<name>to select the child objects matching a name, or all immediate children when using*. Note that thenamecan contain hyphens (-).[<number>]and[*]: Select either a specific element of an array, or all elements of an array.[?(<expr>)]: Filter to select objects that match an expression. This supports all equality operators (=,!=,<,<=,>,>=) and can use@to refer to objects from the current object. For example, to select only fields named “key” that have a numeric value between 42 and 44, you would use$[?(@.key>42 && @.key<44)]
This may seem daunting, but is actually not so difficult in practice. For example, suppose you have the following input-file:

- If you want to extract the first name, you would use path
$.firstName - Similarly,
$.lastNameand$.agewould extract the last name and the age. Note that the age would directly result in a number, because the number is not a string in the original JSON-file. - To extract the city from the address, you would specify
$.address.city, or even simply$..city(which would search for any field city somewhere in the children of the root) - The phone numbers are trickier, because they are an array.
- If you only want to extract the first phone number (e.g. to insert it into some question phone number of an employee), you would use
$.phoneNumbers[0].number— note that the index is zero-based. - If you only want to extract the home-number (e.g. to insert it into some question home phone number of an employee), you would use
$.phoneNumbers[?(@.type="home")].number - If you want to extract all phone numbers (e.g., to insert them into some table with a datafield phone number), you would use
$.phoneNumbers[*].number
- If you only want to extract the first phone number (e.g. to insert it into some question phone number of an employee), you would use
XPath
XPath allows you to extract text from an HTML-page, using the XPath language. This is directly executed in the end-user’s browser, so the full expressivity of the XPath language is available to you — see for example the MDN tutorial on XPath.
Custom function
A custom function allows you to use the full power of Clojure to perform any extraction you want from the content uploaded by the end-user.
The following Clojure vars are available during the execution:
question, containing the raw question for which the data-extraction rule is firedinputcontains the raw input uploaded/pasted by the end-user. Usually it concerns mere text.
You should return either nil (to skip the extraction), or a valid data-type for the target-question (e.g., an IntValue, Date, Duration or string). Note that for table-based questions, you should return a vector containing all the rows of the table (e.g., a vector with IntValue’s).
Generic fields in the data extraction rules
The following fields are available in most data types:
- Description allows you to give a description to your rule. This is merely intended for internal documentation purposes.
- Limit to allows you to limit the scope of the rule to certain kinds of data (e.g., only Word-files or only scanned images). Note that not every combination of Kind and Limit to are possible — e.g., if the Kind is set to Spreadsheet cell, then only Excel-files can be selected from Limit to; similarly, if the Kind is set to JSONPath, only .JSON-files can be selected from Limit to; while XPath can only be used with Text or HTML files.
- Only use with allows you to limit the scope of the rule to a specific language (i.e., the language in which the document displayed at the right side of the Q&A is drafted). After all, you may have very different rules to extract data from French PDF-files or English PDF-files instead.
Standard data conversions
The following data conversions automatically take place:
- Single to multiple. If a single result (“scalar value”) is returned for a table-based question, then this single result is converted into a single-row table. Conversely, if multiple results are returned, while a question expects a single result, the first entry will be taken.
- True/false.
- Number 0 or text “0” will become false
- A null value will become false
- Text “true” / “false” (either in English, or in the document’s current language) will become true or false, irrespective of the capitalisation
- Numbers
- Text values will be converted into whole / floating point numbers if possible
- Conversions from a number or currency to text will use the end-user’s default number formatting settings
- Floating point and whole point numbers will be automatically converted to each other
- Conversions to currency can take place, but will use the end-user’s default currency
- Dates
- Text will be converted to dates or durations if possible, trying both English and the document’s current language.
Pre-processing and post-processing functions
Sometimes it is necessary to perform clean-up or custom conversions. In such case, you can insert custom Clojure-code in the Pre-processing or Post-processing fields.
Pre-processing
Pre-processing code is executed after the initial data extraction has taken place, right before the data conversion takes place into the final data-format of the target question. For example, when the end-user uploads a text-file and a Regex data-extraction rule is defined for a currency-question, the pre-processing code would take place after the Regex has extracted some data, before the conversion from the extracted text to a currency-based number.
When the pre-processing Clojure-code is executed, the following three Clojure-vars are defined:
question, containing the raw question for which the data-extraction rule is firedcontent, containing the result of the data-extraction so far. Usually it concerns mere text, but this is not necessarily the case (e.g., depending on the structure of the JSON-file, a JSONPath extraction may result in a number or an array of text).inputcontains the raw input uploaded/pasted by the end-user. Usually it concerns mere text.
The result of the Clojure-code should be any of the following Clojure values (see also the page with general information about using Clojure within ClauseBase):
- Boolean
- String or vector of strings
- i18 string (for multi-language situations)
- Integer
- FloatValue
- CurrencyValue
- Date
- Duration
The result of the Clojure-code will then be fed into the data-conversion input, except if the result would be nil, in which case it will simply be skipped.
By way of example: Clojure-code may be necessary to:
- convert extracted text to a number:
(ustr/str->int content) - convert extracted text to a date
- determine whether certain content must be skipped despite the successful extraction
Post-processing
Post-processing code is executed after the data-conversion has taken place, right before the data is actually imposed on the relevant answer. You may, for example, want to convert the resulting text to lowercase/uppercase, or remove/add certain prefixes or postfixes.
When the post-processing Clojure-code is executed, the following three Clojure-vars are defined:
question, containing the raw question for which the data-extraction rule is firedcontent, containing the result of the data-extraction and data-conversion.inputcontains the raw input uploaded/pasted by the end-user. Usually it concerns mere text.
(See the section above regarding pre-processing for the expected Clojure output values)
The result of the Clojure-code will then be fed into the question’s answer(s), except if the result would be nil, in which case it will simply be skipped.
Inserting buttons
The final step to prepare your Q&A, is to insert dedicated buttons that enable your end-users to perform a file upload (or drag & drop), or to paste text.
You do this by inserting a new “question” of type Button. (You can optionally rename it to some more relevant name.) It will end up as a simple question with no configuration options:
Typically you will want to insert this “question” at the very beginning of your Q&A, but you actually position it anywhere you want — e.g., in some card with administrative questions, where external data inputs are most relevant.
As is the case with any question, you can attach conditions, so that the buttons can be configured to only appear in certain circumstances.
Towards end-users, this type of “question” will actually show up as two separate buttons:
- End-users can either click on the first button (in which case they will be invited to select a file from their filesystem — e.g. a .XLSX or .PDF file), or drag & drop such file from their filesystem onto the first button.
- Alternatively, users can click on the Paste text button to use any text that is currently loaded into their computer’s clipboard — e.g. copied from an email, Excel-sheet or Word-document, or perhaps even copied by a third-party application such as Salesforce.