General
Tables are collection of cells, organised in rows (horizontally) and columns (vertically). The first row can optionally be assigned the status of a header row, which will be repeated on each page if a table spans multiple pages. All the other rows are called body rows.
In ClauseBase, a simple table with one header row and is created as follows:
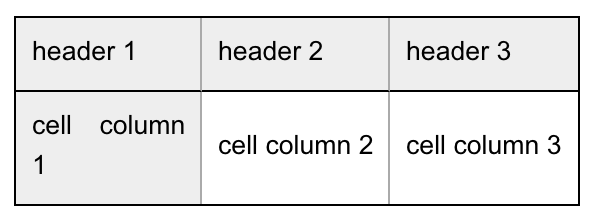
|| header 1 || header 2 || header 3 ||
|| ========== || ----------------- || ---------------- ||
|| cell column 1 || cell column 2 || cell column 3 ||This will result in the following table:
A more complex example:
|| header 1 || header 2 || header for righ-aligned column ||
|| ------------ || --------------- || ------------------------------: ||
|| cell column 1 || cell column 2 || cell column 3 ||
||> merged cell columns 1 & 2 || regular cell ||
||>> merged all cells ||
|| regular cell 1 || vertically merged || regular cell 3 ||
|| regular cell 1 ||^ || regular cell 3 ||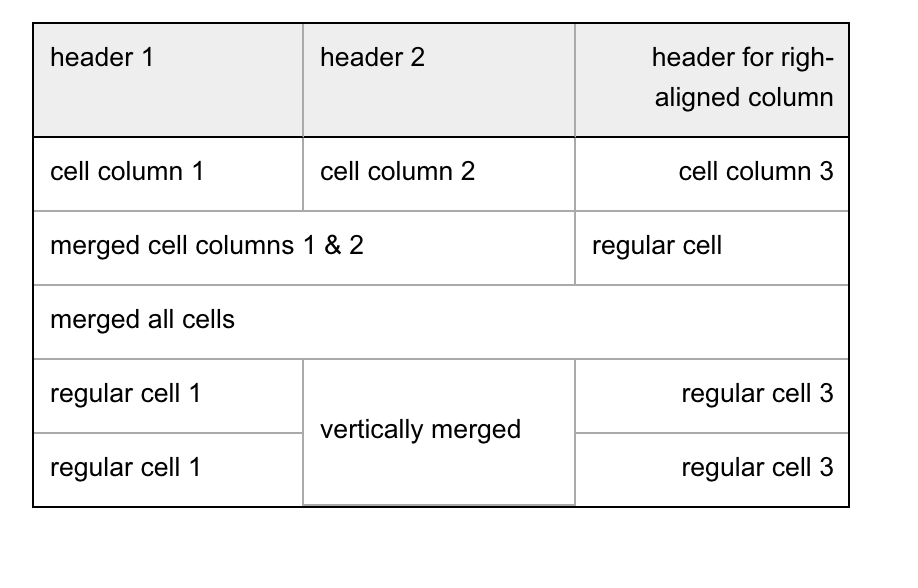
Some general notes:
- Each cell is separated by a double pipe symbol (||).
- Rows are separated by a newline (i.e., pressing Enter).
- It is no problem for a row to span multiple lines in the text editor, e.g. because there are too many columns to fit on one line of ClauseBase’s text editor.
- You can have maximum one blank line between rows of the same table. If you insert at least two blank lines between rows, then a new table will be started.
- It is not necessary to line up the double pipe symbols between lines, although it will of course be much cleaner to like at in the editor. In the .DOCX or .PDF file, this will however not make any difference.
- The first row will be treated as a header row if it is followed by a divider row that contains cells with either multiple dashes (—-), or multiple equal-signs (====). There should be at least three dashes / equal-signs, but no upper limit applies.
- If a column in the divider row contains equal-signs, then all the cells in that column will have a light grey background. In the example above, this is the case for the first column.
- Whether the table contains borders, and whether it is left-aligned, center-aligned, right-aligned or instead stretched across the entire width of the page, can be changed in the base styling.
Automatically reformatting a table
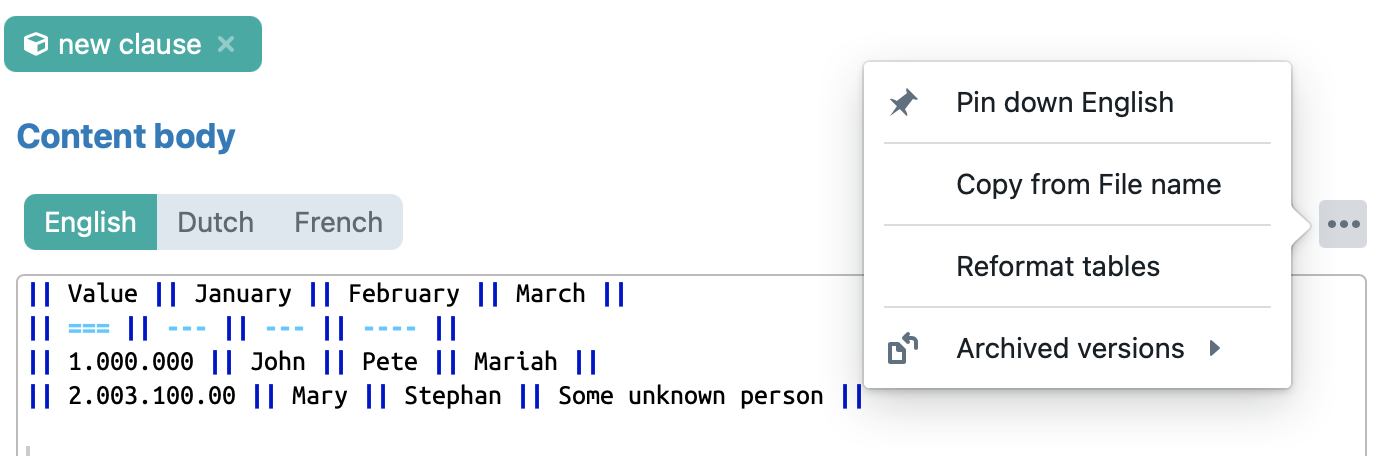
You can automatically reformat how a table looks inside the ClauseBase grammar:

by pressing “reformat tables” in the popup-menu at the right side:
becomes

Inserting large amounts of text
If you want to insert multiple paragraphs into a single cell, you have to use the internal inclusions mechanism. After all, remember that inserting a newline (Enter) would start a new row of the table…
Example:
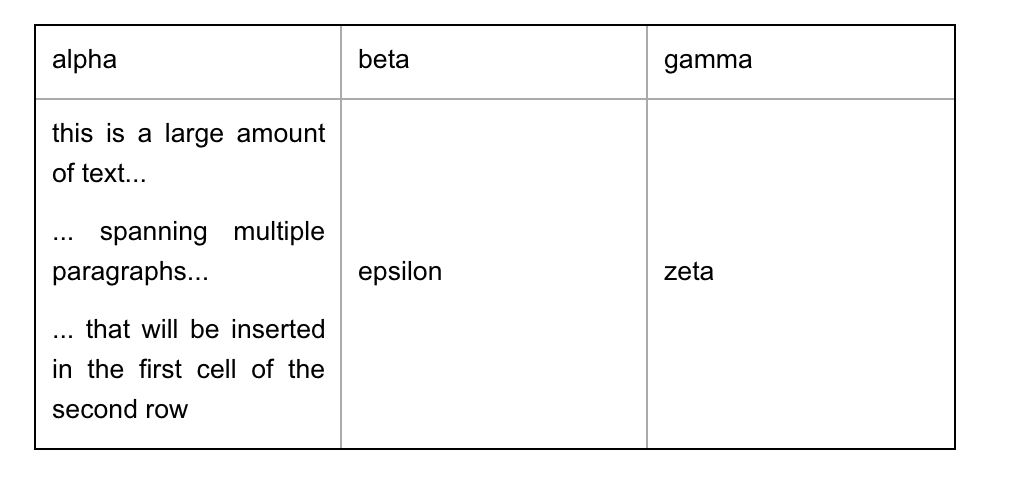
|| alpha || beta || gamma ||
|| @DELTA || epsilon || zeta ||
DELTA = this is a large amount of text...
... spanning multiple paragraphs...
... that will be inserted in the first cell of the second rowresults in:
Alignment of cells
The dashes or equal-signs in the divider row can optionally contain a colon (:) before the first dash/equal-sign and/or after the first dash/equal-sign. The presence of these colons will cause all the cells in that column to be left, center or right-aligned, respectively. For example:
:—--or:===will cause the cells to be left-aligned:—--:or:===:will cause the cells to be center-aligned---:or===:will cause the cells to be right-aligned- no colon will cause the cells to receive the general alignment specified in the styling (typically left-aligned or justified).
Merging columns (horizontal cell merging)
A cell can optionally span multiple columns. This can be achieved by inserting one or more larger-than symbols (>) immediately after the double pipe (without any space in between).
Example:
|| alpha || beta || gamma ||
||>> delta
|| epsilon || zeta || eta ||will be outputted as:
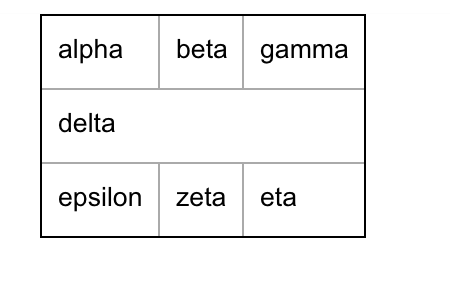
Merging rows (vertical cell merging)
A cell can optionally be merged with the cell above it. This can be achieved by inserting a caret symbol (^) after the double-pipes. The cell must not contain any other content. Example:
|| alpha || beta || gamma ||
||^ || delta || epsilon ||will be outputted as:
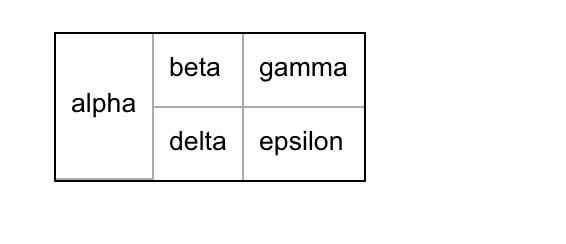
Note that horizontal and vertical merging can be combined. The cell that contains the caret will then have the same horizontal merging amount as the above cell it is merged with. Example:
|| alpha || beta || gamma ||
||> delta || epsilon ||
||^ || zeta ||will be outputted as:
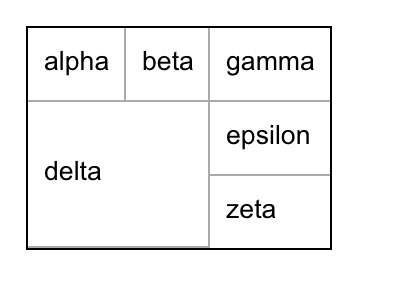
Conditional rows
Each body row can optionally contain a condition that will determine whether or not the row will be shown. This condition can be any valid condition, needs to be surrounded by curly brackets, and needs to be inserted after the last set of double-pipes. For example:
Example:
|| alpha || beta ||
|| ---- || ---- ||
|| gamma || delta || {#deal^value > 5000 EUR}
|| epsilon || zeta || {#deal^value <= 5000 EUR}In this example, the row with cells gamma and delta will only be shown if the #deal^value data-field happens to be larger than 5000 EUR. If not, the row with epsilon and zeta will be shown.
Conditional columns
Similar to rows, columns can also be made conditional, by inserting a condition in curly brackets on the first row of the table. For example:
|| {#deal^value > 5000 EUR} || ||
|| alpha || beta ||
|| ---- || ---- ||
|| gamma || delta ||
|| epsilon || zeta ||The first column will not be shown if the #deal^value data-field contains a value lower than 5000 EUR.
Repeating rows
A row will be automatically repeated if it contains at least one repeating data-field (hence the name of this type of data-field). The row will then be repeated for as many times as there are values in the repeating data-field. (If multiple repeating data-fields are used, then the repetition-amount will be equal to the amount of the repeating data-field with the largest amount of repeating data-fields)
For example, assume that the #item^name, #item^price and #item^quantity data-fields are all repeating-fields, containing the following values:
- #item^name: alpha, beta, gamma and delta
- #item^price: 100 EUR, 200 EUR, 300 EUR and 400 EUR
- #item^quantity: 1, 2 and 3.
The following table:
|| name || price || quantity ||
|| ==== || ----- || -------------- ||
|| #item^name || #item^price || #item^quantity ||will then result in the following output:
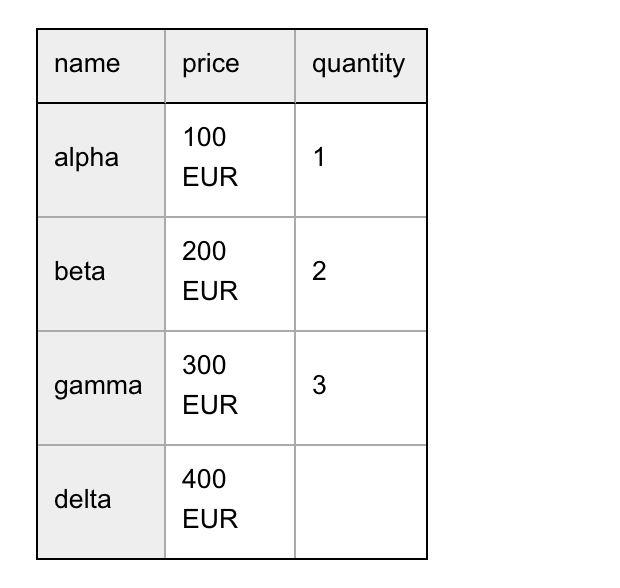
Notice that the quantity of delta is not filled in, because the #item^quantity data-field only contained three items.
Do not use repeating fields from multiple concepts in the same row, as this is ambiguous (you will get an error message about “multiple repeating-lists in the same row”). After all, which of the concepts data should then be used to calculate the number of rows?
Layout settings
In the “Table Settings” of the Base styling (which you can always add to a specific clause through the custom styling option) you can specify various options for tables, such as a table’s alignment, width, borders, background and text flow.